Gradient Descent 의 문제
1.너무 신중하게 방향을 선택한다.
- 모든 데이터의 방향을 전부 고려해서 loss 값을 편미분하여 gradient를 구하기 때문이다.
- 데이터가 100만 개라면 100만 번 해줘야 한다...
이는 연산이 너무 많아져 gradient의 한 step을 update하려면 너무 오랜 시간이 걸린다.
2. Local Mininum에 빠진다.
- alpha를 잘 잡았다면 가장 가까운 로컬 미니멈에 가기에 global minimum에 못갈 수 있다.
첫사랑과 결혼할 수 있지만 그게 바로 최고의 선택일까? (이 예시는 혁펜하임의 예시이므로 나와는 전~혀 상관없다) ㅋㅋㅋ
여러 개의 케이스가 있을 때 더 나은 솔루션으로 갈 수 있는 경우가 존재한다.
Stochastic Gradient Descent
위와 같은 문제를 해결하려면 stochastic gradient descent를 사용한다.
확률적 경사 하강법(SGD)은 랜덤하게 데이터 하나를 뽑아서 로스를 구하고, 그것을 가지고 gradient를 구해서 update 한 스텝을 진행한다.
기존에는 모든 데이터를 전부 고려해서 gradient를 모두 업데이트 해야하므로 연산이 오래걸렸으나,
SGD는 랜덤하게 추출한 데이터를 가지고 loss를 구해 gradient 업데이트 하므로 연산이 빠르다.
충분히 수렴할 때까지, 즉 미분이 충분히 작아질 때까지 SGD를 구하게 된다.
이때 적당한 반복횟수를 정해주어야 하는데, 이를 epoch이라고 한다.

위 그림을 보면, Graident Descent와 SGD의 차이를 볼 수 있다.
이때 왜 SGD의 첫번째 step은 gradient descent의 방향과 다를까? 결국 우리의 최종 목표는 global minimum인 + 인데, 왜 SGD는 그쪽으로 첫 스텝을 가지 않았을까?
그것은 SGD가 언제나 가장 가파른 곳으로 이동하는 성질을 가지고 있기 때문이다.
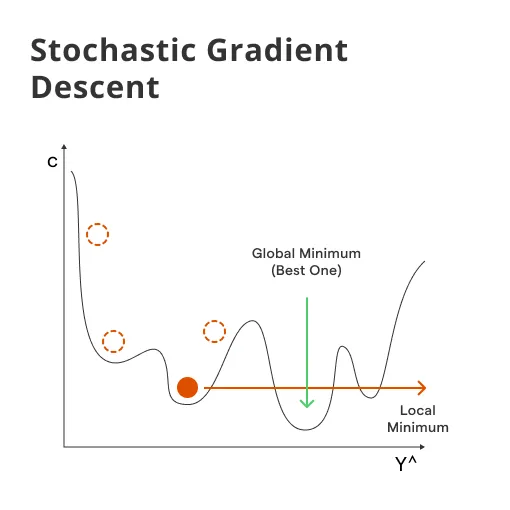
이 그림을 그대로 보면, 가장 가파른 곳이 잘 보인다. 그런데 이 그림을 3차원이라고 생각하고 위에서 바라볼 때 등고선을 그려보자. 그렇다면 위에 있는 동그란 등고선과 같게 볼 수 있다. 즉, SGD가 가장 가파른 방향으로 움직인다 는 것이 무엇을 의미하는 지 이해할 수 있다.
SGD가 가장 가파른 곳으로 움직이므로, Gradient Descent보다 global minimum에 수렴할 확률이 높아진다.
mini-batch SGD
그런데, SGD는 데이터를 하나씩 보니까 너무 성급한 방향 결정이라고 볼 수 있다. 불필요한 움직임일 수 있다는 것이다.
이때 mini-batch SGD를 사용한다.
이전에 데이터를 하나씩 보는 것과 달리, 2개 이상의 데이터를 가지고 SGD를 수행하는 것이 mini-batch SGD이다.
그러니 mini-batch 사이즈를 키우면 키울수록 SGD가 아닌 Gradient Descent 스럽게 진행된다.
GPU를 사용해 병렬 연산을 가능하게 하므로 여러 데이터에 대해서 빠르므로 연산이 빠르다.
그렇지만 batch size는 8K까지만 키우는 것이 좋다.

batch size를 키울수록 gradient descent에 가까워지므로, 그것의 문제인 local minimum의 문제를 답습하게 된다. (연산은 GPU 병렬처리로 해결 가능하다)
Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., ... & He, K. (2017). Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677. 에서는 그 문제를 해결하려면 learning rate를 키우고, warmup도 해야한다고 한다.
1. batch size를 두 배 키웠을 때 learning rate도 두배 키워야 한다.
mini-batch SGD에서는 batch 안에 있는 여러 데이터의 gradient를 평균내서 사용한다.
예를 들어 batch size가 32이면 32개의 데이터로 gradient를 평균내고, batch size가 64이면 64개의 데이터로 평균 gradient를 계산한다.
batch size가 커질수록 더 많은 데이터를 보고 평균을 내기 때문에 gradient의 방향이 덜 흔들리고(noise 감소) 더 안정적인 업데이트가 가능해진다. 그래서 batch size를 2배 늘리면 learning rate도 보통 2배 정도 늘려서 더 크게 이동하도록 설정하는 경우가 많다.
이를 linear scaling rule이라고 부르며, 대규모 딥러닝 학습에서 자주 사용되는 경험적인 규칙이다. 다만 항상 정확하게 성립하는 것은 아니며, 너무 큰 learning rate를 사용하면 오히려 학습이 불안정해질 수도 있다.
2. learning rate에 대해 warm up을 한다.
학습 초반에는 parameter가 아직 안정적인 방향을 찾지 못한 상태이므로 gradient가 크게 흔들릴 수 있다. 이때 처음부터 큰 learning rate를 사용하면 loss가 발산하거나 학습이 불안정해질 수 있다.
그래서 초반 몇 step 또는 몇 epoch 동안은 작은 learning rate에서 시작해서 점진적으로 learning rate를 증가시키는데, 이를 warmup이라고 한다. 보통 warmup은 learning rate를 0 또는 매우 작은 값에서 시작해서 목표 learning rate까지 선형(linear)으로 증가시키는 방식이 많이 사용된다.
이후에는 학습이 진행되면서 learning rate를 다시 감소시키는데, 이때 cosine decay, step decay 같은 learning rate scheduler를 함께 사용하기도 한다.

warmup과 learning rate scaling 같은 기법은 large batch training에서 자주 함께 사용된다. 일반적으로 batch size가 커질수록 gradient의 noise가 감소하여 학습은 더 안정적이고 빠르게 진행될 수 있다.
하지만 batch size가 지나치게 커지면 gradient의 stochasticity가 줄어들어 sharp minimum에 수렴하기 쉬워지고, 이로 인해 test 성능이나 generalization 성능이 나빠질 수 있다.
반대로 작은 batch size는 gradient noise가 더 크기 때문에 학습 과정에서 일종의 regularization 효과를 만들 수 있으며, 더 좋은 generalization 성능을 보이는 경우가 많다.
이것을 한마디로 표현하자면 작은 batch는 gradient에 noise가 많아 다양한 방향을 탐색하게 만들고, 이것이 일반화 성능에 도움을 줄 수 있다. 반면 큰 batch는 안정적으로 수렴하지만 sharp minimum에 빠져 generalization 성능이 나빠질 수 있다.
Momentum
mini-batch SGD도 문제점이 존재한다.
Gradient는 contour line(등고선)에 항상 수직인 방향을 가진다.
이는 현재 위치에서 loss가 가장 가파르게 증가하는 방향이며, 반대로 negative gradient 방향은 loss가 가장 빠르게 감소하는 방향이다.
하지만 SGD는 현재 순간의 gradient만 보고 이동하기 때문에, 특히 경사가 좁고 긴 골짜기 형태일 경우 좌우로 크게 진동하는 문제가 발생할 수 있다. 즉, 최적점으로 향하기보다는 지그재그 형태로 비효율적으로 이동하게 된다.
이를 개선하기 위해 momentum을 사용한다.
Momentum은 현재 gradient뿐 아니라 이전 step들에서의 gradient 방향도 함께 누적하여 업데이트에 반영하는 방법이다.
gradient의 지수 이동 평균(exponential moving average)을 유지하는 방식이라고 할 수 있다.
즉, 시간축 방향으로 gradient 정보를 누적하여 일종의 관성(inertia)을 부여하는 것이다.
그래서 특정 방향으로 gradient가 계속 유지되면 그 방향으로는 점점 더 빠르게 이동하고, 반대로 좌우로 반복적으로 방향이 바뀌는 진동은 서로 상쇄되어 줄어들게 된다.
결과적으로 momentum은 SGD의 진동을 줄이고, 더 빠르고 안정적으로 최적점에 수렴하도록 도와준다.

RMS Prop
RMSProp은 parameter마다 서로 다른 learning rate를 적용하는 optimizer이다.
기존 SGD는 모든 parameter에 동일한 learning rate를 사용한다. 따라서 어떤 방향에서는 너무 크게 움직이고, 다른 방향에서는 너무 느리게 움직일 수 있다.
하지만 RMSProp은 gradient의 크기를 누적해서, 각 parameter마다 learning rate를 자동으로 조절한다. gradient 크기를 기준으로 각 방향의 업데이트 크기를 자동으로 조절한다.
RMSProp은 gradient의 제곱값을 누적하여 gradient magnitude를 추적한다. 즉, gradient의 방향보다는 “얼마나 큰 gradient가 반복적으로 발생하는가”를 보는 방식이다.
그래서 gradient가 계속 크게 나오는 방향에서는 업데이트 크기를 줄이고, gradient가 작은 방향에서는 업데이트 크기를 상대적으로 크게 만든다.
직관적으로 보면 경사가 가파른 방향에서는 조심스럽게 이동하고, 경사가 완만한 방향에서는 더 크게 이동하는 것이다.
결과적으로 RMSProp은 parameter마다 서로 다른 step size를 사용하게 되며, 학습을 더 안정적이고 효율적으로 만든다.
특히 loss surface가 좁고 긴 골짜기 형태일 때, 가파른 축에서는 진동을 줄이고 완만한 축에서는 더 빠르게 이동할 수 있도록 도와준다.

Adam (Adaptive Moment Estimation)

Adam(Adaptive Moment Estimation)은 Momentum과 RMSProp의 아이디어를 결합한 optimizer이다.
이름 그대로 gradient의 moment를 추정해서 parameter를 업데이트한다.
여기서 1차 moment는 gradient의 평균, 즉 방향 정보를 의미하고, 2차 moment는 gradient 제곱의 평균, 즉 크기 정보를 의미한다.
Adam의 최종 업데이트 식은 다음과 같다.
$$
\theta_t \leftarrow \theta_{t-1} - \alpha \cdot \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}
$$
이 식은 기존 gradient descent의 업데이트 식을 확장한 형태라고 볼 수 있다. 기존에는 현재 gradient에 learning rate를 곱해서 parameter를 업데이트했다면, Adam은 분자와 분모에 각각 다른 정보를 넣어 업데이트 방향과 크기를 조절한다.
먼저 분자에 있는 \(\hat{m}_t\)는 gradient의 1차 모멘트, 즉 momentum을 의미한다. 현재 gradient만 사용하는 것이 아니라 이전 step들의 gradient를 지수이동평균으로 누적해서 사용한다. 따라서 과거의 gradient 방향까지 함께 고려하여 관성을 가진 방향으로 업데이트할 수 있다.
반면 분모에 있는 \(\sqrt{\hat{v}_t} + \epsilon\)은 RMSProp의 아이디어를 반영한 부분이다.
\(\hat{v}_t\)는 gradient를 element-wise로 제곱한 값을 누적한 것이다.
gradient를 제곱하면 부호는 사라지고 크기 정보만 남기 때문에, \(\hat{v}_t\)는 각 parameter 방향에서 gradient가 얼마나 크게 발생했는지를 나타낸다.
이 값을 제곱근으로 만든 뒤 분모에 넣으면, gradient가 자주 크게 발생한 방향에서는 업데이트 크기가 작아지고, gradient가 작게 발생한 방향에서는 상대적으로 업데이트 크기가 커진다. 즉, 가파른 방향에서는 조심스럽게 이동하고, 완만한 방향에서는 더 과감하게 이동하도록 조절하는 것이다.
마지막으로 \(\epsilon\)은 분모가 0에 가까워지는 것을 막기 위한 작은 양수이다.
분모가 너무 작아지면 업데이트 값이 비정상적으로 커질 수 있으므로, \(\epsilon\)을 더해 수치적으로 안정적인 업데이트가 되도록 한다.
엡실론은 어떤 parameter의 gradient variance가 극도로 작으면 adaptive scaling 때문에 learning rate가 지나치게 커질 수 있는문제를 완화한다.
그러니까 엡실론은 1) divide-by-zero를 방지하고, 2) 지나친 adaptive scaling을 억제한다.
정리하면 Adam은 분자에서는 momentum을 통해 방향의 관성을 반영하고, 분모에서는 RMSProp을 통해 각 parameter별 step size를 조절한다. 즉, Adam은 momentum과 RMSProp을 결합한 optimizer라고 볼 수 있다.
'STUDY > ML DL' 카테고리의 다른 글
| numpy : 배열 연산, 사칙연산, 원소별 곱, 행렬곱 (0) | 2026.05.08 |
|---|---|
| numpy : ndarray, random, randn, rand, shape, dim, size, zeros, ones, arange, linspace (1) | 2026.05.08 |
| 인공신경망 이해하기 (0) | 2026.04.30 |
| 강화 학습 Reinforcement Learning (1) | 2026.04.30 |
| 자기지도 학습 Self-supervised Learning, Contrastive Learning (0) | 2026.04.30 |