강화학습은 “여러 번의 선택을 통해 어떤 행동이
장기적으로 가장 좋은 결과를 만드는지 배우는 과정”이다.
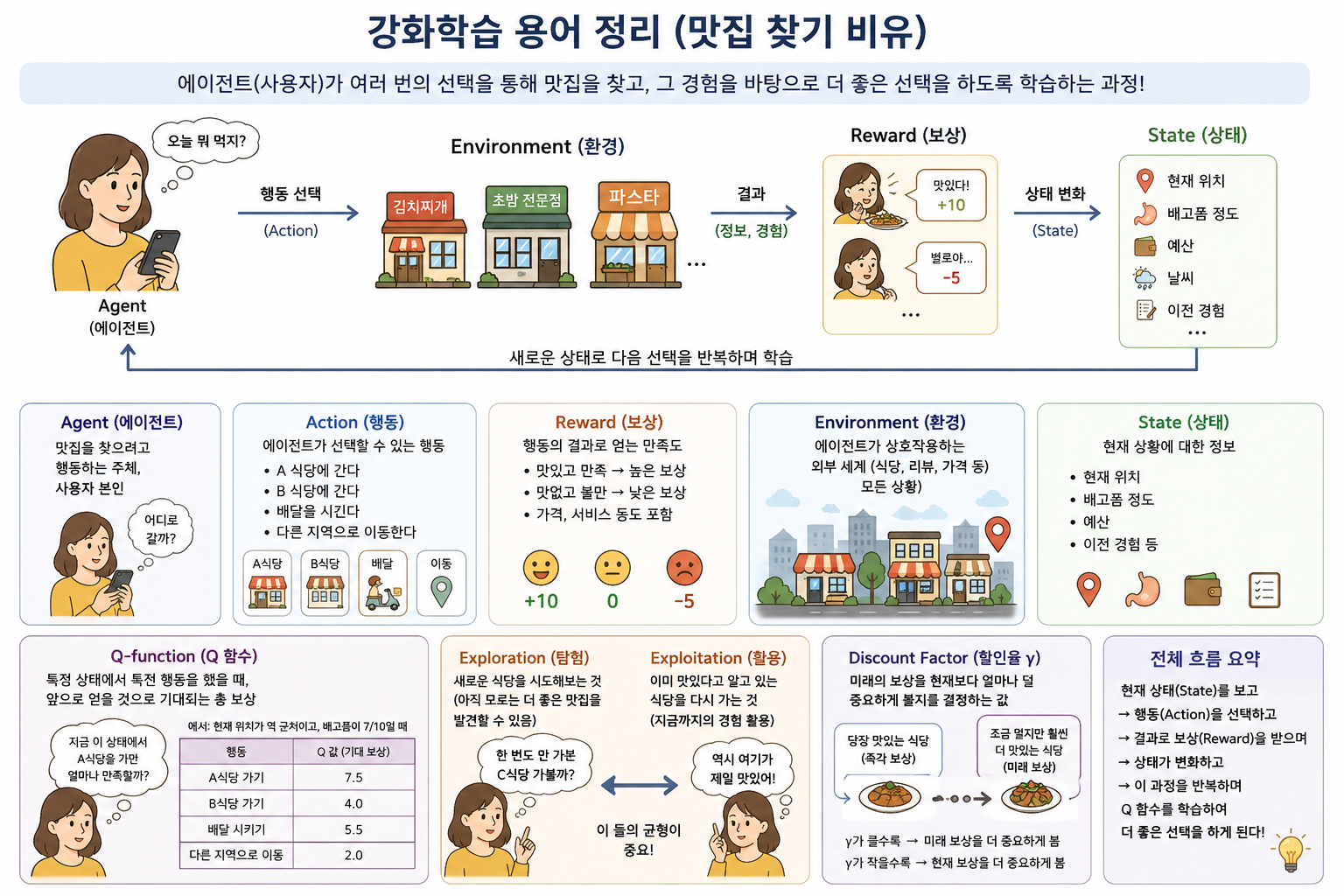
맛집을 찾는 과정을 통해 강화학습의 주요 개념을 설명할 수 있다. 여기서 중요한 점은, 한 번의 선택이 아니라 여러 번의 선택을 반복하면서 점점 더 좋은 선택을 하도록 학습한다는 것이다.
agent (에이전트)
맛집을 찾으려고 행동하는 주체, 즉 사용자 본인이다.
어떤 식당을 선택할지 결정하는 의사결정자이다.
environment (환경)
에이전트가 상호작용하는 외부 세계이다.
예를 들어 음식점 목록, 위치, 가격, 리뷰, 그리고 실제 식사 경험까지 포함된 전체 상황을 의미한다.
state (상태)
현재 상황에 대한 정보이다.
예를 들어 “현재 위치”, “배고픔 정도”, “예산”, “이전에 방문한 식당 경험” 등이 상태에 해당한다.
action (행동)
에이전트가 선택할 수 있는 행동이다.
예를 들어 “A 식당에 간다”, “B 식당에 간다”, “배달을 시킨다” 등이 있다.
reward (보상)
행동의 결과로 얻는 만족도이다.
음식이 맛있으면 높은 보상, 맛이 없으면 낮은 보상을 받는다.
가격 대비 만족도, 서비스 등도 포함될 수 있다.
Q-function (Q 함수)
특정 상태에서 특정 행동을 했을 때, 앞으로 얻을 것으로 기대되는 총 보상을 의미한다.
예를 들어,
“지금 배고프고 근처에 있을 때 A 식당을 가면 얼마나 만족할까?”
를 수치로 나타낸 것이 Q 값이다.
즉, “이 선택이 장기적으로 얼마나 좋은 선택인가?” 를 평가하는 함수이다.
exploration (탐험)
새로운 식당을 시도해보는 것이다.
아직 가보지 않은 식당이 더 맛있을 수도 있기 때문에 필요하다.
exploitation (활용)
이미 맛있다고 알고 있는 식당을 다시 가는 것이다.
현재까지의 경험을 활용하는 전략이다.
강화학습에서는 이 둘의 균형이 중요하다.
discount factor (할인율)
미래의 보상을 현재보다 얼마나 덜 중요하게 볼지를 결정하는 값이다.
예를 들어,
- 당장 맛있는 식당 (즉각 보상)
- 조금 멀지만 훨씬 더 맛있는 식당 (미래 보상)
이 중 무엇을 더 중요하게 볼지를 결정한다.
할인율이 크면 미래 보상을 중요하게 보고, 작으면 현재 보상을 더 중요하게 본다.
ε-greedy (입실론 그리디) 전략
강화학습에서 중요한 문제 중 하나는 exploration(탐험)과 exploitation(활용) 사이의 균형이다.
- exploration은 새로운 행동을 시도하여 더 나은 선택지를 찾는 과정이고,
- exploitation은 지금까지의 경험을 바탕으로 가장 좋은 선택을 반복하는 과정이다.
이 둘 중 어느 하나에만 치우치게 되면 문제가 발생한다.
탐험만 수행하면 비효율적인 시도가 반복되고, 활용만 수행하면 더 좋은 선택지를 발견하지 못하게 된다.
이러한 문제를 해결하기 위한 가장 기본적인 방법이 ε-greedy 전략이다.
ε-greedy 전략의 핵심은 매우 단순하다.
일정 확률 ε로는 무작위 행동을 선택하고,
나머지 확률 (1 - ε)로는 현재까지 가장 좋은 행동을 선택한다.
이를 수식으로 표현하면 다음과 같다.
- 확률 ε → 임의의 행동 선택 (exploration)
- 확률 (1 - ε) → 현재 상태에서 Q값이 가장 큰 행동 선택 (exploitation)
이를 맛집 탐색에 비유해보면 다음과 같다.
이미 여러 번 방문해 본 결과 가장 만족스러웠던 식당이 있다고 하자. 이 경우 대부분의 상황에서는 해당 식당을 다시 방문하는 것이 합리적인 선택이다.
그러나 항상 같은 선택만 반복한다면, 더 좋은 식당이 존재하더라도 이를 발견할 수 없다. 따라서 일정 확률로는 새로운 식당을 시도해볼 필요가 있다.
예를 들어 ε = 0.1이라면,
- 90% 확률로는 기존에 가장 만족도가 높았던 식당을 선택하고,
- 10% 확률로는 새로운 식당을 시도하게 된다.
이처럼 ε-greedy는 탐험과 활용을 확률적으로 섞어 사용하는 방식이다.
또한 실제 학습 과정에서는 ε 값을 고정하지 않고 점진적으로 감소시키는 방법을 자주 사용한다.
초기에는 환경에 대한 정보가 부족하기 때문에 탐험의 비중을 높게 두고, 학습이 진행될수록 점차 활용의 비중을 높이는 방식이다.
이를 ε 감소 전략(ε decay)이라고 한다.
예를 들어,
- 초기: ε = 1.0 (거의 모든 행동을 탐험)
- 중간: ε = 0.3
- 후반: ε = 0.05 (대부분 활용)
과 같은 형태로 설정할 수 있다.
다만 ε-greedy는 구조가 단순한 만큼 몇 가지 한계를 가진다.
첫째, 탐험이 무작위로 이루어지기 때문에 비효율적인 행동이 반복될 수 있다.
둘째, 이미 충분히 좋은 선택을 알고 있는 경우에도 일정 확률로 불필요한 탐험이 발생한다.
그럼에도 불구하고 구현이 간단하고 직관적이기 때문에, 강화학습의 기초 단계에서 가장 널리 사용되는 탐험 전략 중 하나이다.
정리하면, ε-greedy 전략은 탐험과 활용 사이의 균형 문제를 해결하기 위해, 일정 확률로 무작위 행동을 선택하는 간단한 방법이다. 이를 통해 에이전트는 기존의 지식을 활용하면서도 새로운 가능성을 지속적으로 탐색할 수 있다.
Q-learning
앞서 ε-greedy 전략을 통해, 에이전트는 탐험과 활용을 적절히 섞으며 행동을 선택할 수 있다.
그렇다면 다음 질문이 자연스럽게 등장한다.
“어떤 행동이 좋은 선택인지(Q값)는 어떻게 학습하는가?”
이를 해결하는 대표적인 방법이 Q-learning이다.
Q-learning은 상태(state)와 행동(action)의 조합에 대해, 해당 행동이 얼마나 좋은 선택인지를 나타내는 Q값(Q-value)을 학습하는 알고리즘이다.
Q값은 특정 상태에서 특정 행동을 했을 때, 앞으로 얻을 것으로 기대되는 총 보상이다.
이 Q값은 한 번에 알 수 있는 것이 아니라, 에이전트가 환경과 상호작용하면서 점진적으로 업데이트된다.
업데이트 핵심은 현재 얻은 보상과, 다음 상태에서의 최적 선택을 반영하여 Q값을 수정한다.
이를 수식으로 표현하면 다음과 같다.
$$ Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right] $$
각 요소의 의미는 다음과 같다.
- \( s \): 현재 상태 \\
- \( a \): 현재 행동 \\
- \( r \): 현재 행동으로 얻은 보상 \\
- \( s' \): 다음 상태 \\
- \( \alpha \): 학습률 (learning rate) \\
- \( \gamma \): 할인율 (discount factor)
이 식을 직관적으로 해석하면 다음과 같다.
“현재 생각했던 가치(Q값)”와
“실제로 경험한 결과(보상 + 미래 기대값)”의 차이를 줄여가는 과정
즉, 모델은 자신의 예측을 실제 경험에 맞게 계속 수정해 나간다.
맛집 비유로 이해하기
현재 상태가 “배고프고, 특정 지역에 있음”이라고 하자.
이 상태에서 A 식당을 선택했다.
- 음식이 맛있었다 → 보상 rr이 높음
- 이후 상태에서도 좋은 선택이 가능 → 미래 기대값도 높음
이 경우 해당 상태에서 A 식당의 Q값은 증가한다.
반대로,
- 음식이 별로였다 → 보상 낮음
- 이후 선택도 좋지 않음
이라면 Q값은 감소하게 된다.
이 과정을 반복하면, 에이전트는 점점 더 좋은 선택을 하게 된다.
처음에는 무작위에 가까운 선택을 하더라도 시간이 지날수록 높은 Q값을 가진 행동을 더 자주 선택하게 된다.
이때 ε-greedy 전략이 함께 사용되면서
- 일부는 탐험하며 새로운 정보를 얻고
- 일부는 기존에 학습한 좋은 선택을 활용하게 된다.
강화학습의 흐름을 정리하면 다음과 같다.
- 현재 상태(state)를 관찰한다.
- ε-greedy 전략을 통해 행동(action)을 선택한다.
- 행동 결과로 보상(reward)과 다음 상태를 얻는다.
- Q-learning 식을 통해 Q값을 업데이트한다.
- 이 과정을 반복하면서 점점 더 나은 정책을 학습한다.
'STUDY > ML DL' 카테고리의 다른 글
| numpy : 배열 연산, 사칙연산, 원소별 곱, 행렬곱 (0) | 2026.05.08 |
|---|---|
| numpy : ndarray, random, randn, rand, shape, dim, size, zeros, ones, arange, linspace (1) | 2026.05.08 |
| SGD와 mini-batch SGD, Momentum과 RMSProp 기반 Adam (0) | 2026.05.08 |
| 인공신경망 이해하기 (0) | 2026.04.30 |
| 자기지도 학습 Self-supervised Learning, Contrastive Learning (0) | 2026.04.30 |