IP
네트워크 계층에서 가장 중요한 프로토콜을 하나만 고르라면 보통 IP(Internet Protocol)를 말할 수 있다.
IP는 네트워크 계층에 속한 대표적인 프로토콜이다. 물리 계층과 데이터 링크 계층만으로는 같은 네트워크 안의 장치끼리 통신하는 데 한계가 있다. 다른 네트워크에 있는 호스트까지 메시지를 전달하려면 네트워크를 넘어 목적지를 찾아갈 수 있어야 한다.
이때 사용되는 프로토콜이 IP이다.
IP를 사용하면 IP 주소를 통해 송신지와 수신지를 지정할 수 있고, 패킷이 목적지까지 이동할 경로를 결정하는 라우팅에도 활용할 수 있다.
IP에는 여러 버전이 있다. 대표적으로 IPv4와 IPv6이 있다. 현재도 IPv4가 널리 사용되고 있으므로, 먼저 IPv4를 중심으로 살펴보고자 한다.
IP의 주요 기능
IP의 공식적인 주요 기능은 크게 두 가지로 볼 수 있다.
주소 지정 IP addressing
단편화 IP fragmentation
주소 지정은 IP 주소를 이용해 특정 네트워크에 속한 특정 호스트를 식별하는 기능이다.
단편화는 큰 IP 패킷을 한 번에 전송 가능한 크기 이하로 나누는 기능이다.
참고로 IP 같은 인터넷 관련 기술은 RFC 문서에 정의되어 있다. RFC는 인터넷 기술에 대한 제안, 설명, 표준 등을 담은 문서이다.
IPv4 주소 지정
주소 지정은 IP 주소를 바탕으로 송신지와 수신지를 정하는 기능이다.
IP 주소는 단순히 하나의 컴퓨터만 가리키는 값처럼 보일 수 있지만, 실제로는 두 가지 정보를 포함한다.
호스트가 속한 네트워크
그 네트워크 안의 특정 호스트
IPv4 주소는 32비트, 다시 말해 4바이트로 표현된다.
사람이 읽기 쉽게 표기할 때는 8비트씩 끊어서 10진수로 나타낸다. 각 숫자는 점으로 구분한다.
192.168.0.1
여기서 점으로 구분된 각 부분은 8비트이다.
8비트로 표현할 수 있는 값의 범위는 0부터 255까지이다.
이처럼 점으로 구분된 8비트 단위를 옥텟(octet)이라고 한다.
IPv4 주소는 네 개의 옥텟으로 구성된다.
IP 단편화
IP의 또 다른 기능은 단편화이다.
단편화(fragmentation)는 전송하려는 IP 패킷이 너무 클 때, 이를 더 작은 여러 패킷으로 나누는 작업이다.
네트워크에서는 한 번에 전송할 수 있는 패킷의 최대 크기가 정해져 있다.
이를 MTU(Maximum Transmission Unit)라고 한다.
IP 패킷의 크기는 MTU보다 작거나 같아야 한다.
여기서 IP 패킷의 크기에는 IP 헤더도 포함된다.
일반적인 이더넷 환경에서 MTU는 보통 1500바이트이다.
전송하려는 IP 패킷이 이보다 크면 여러 개의 작은 패킷으로 나누어 전송해야 한다.

나누어진 패킷들은 수신지에 도착한 뒤 다시 원래 데이터로 재조합된다.
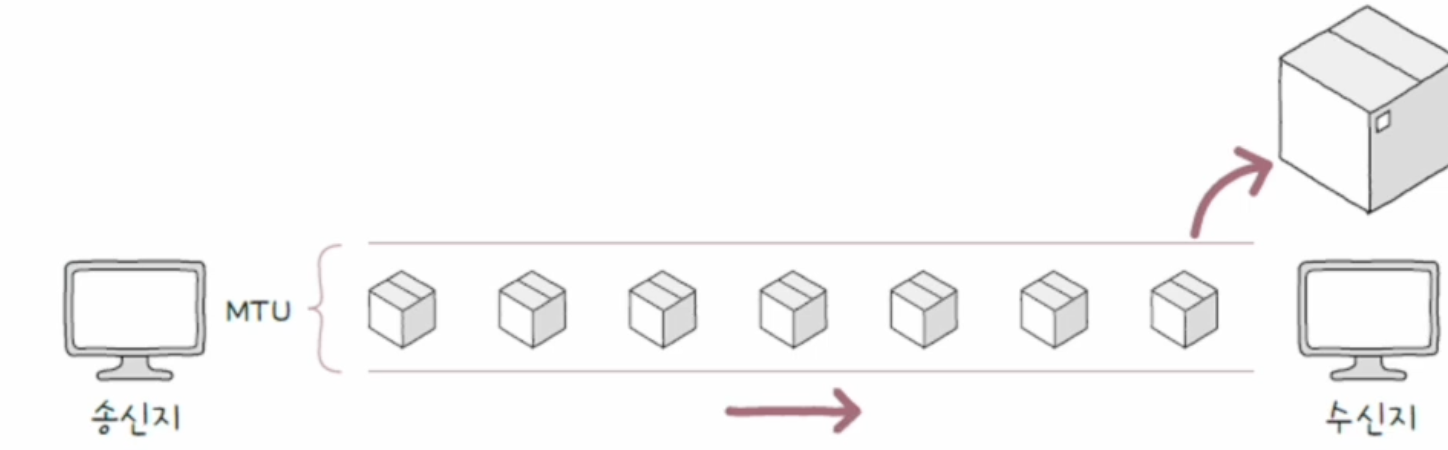
이더넷 프레임과 MTU
IPv4 패킷은 데이터 링크 계층의 프레임 안에 담겨 전송된다.
예를 들어 이더넷에서는 IPv4 패킷이 이더넷 프레임의 데이터 필드에 들어간다.
이더넷 프레임에서 데이터 필드의 일반적인 최대 크기는 1500바이트이다.
이 크기를 넘는 IP 패킷은 그대로 담을 수 없으므로 단편화가 필요할 수 있다.
IP 패킷은 IP 헤더와 데이터를 포함한다.
이 전체 크기가 MTU보다 커지면 단편화가 이루어진다.

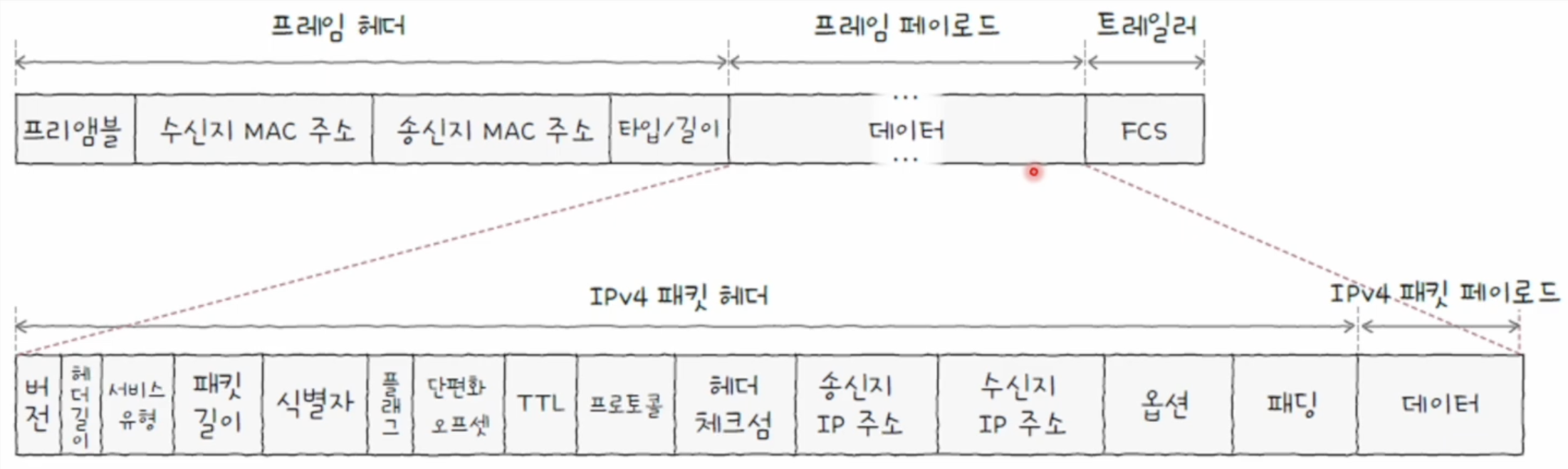
IPv4 패킷의 핵심 필드
IPv4 패킷에는 여러 필드가 있다.
그중 단편화, 수명 관리, 상위 프로토콜 식별, 주소 지정과 관련해 중요한 필드를 중심으로 보면 다음과 같다.
식별자
플래그
단편화 오프셋
TTL
프로토콜
송신지 IP 주소
수신지 IP 주소

식별자
식별자(identifier)는 패킷에 할당된 고유한 번호이다.
단편화가 발생하면 하나의 IP 패킷이 여러 조각으로 나뉘어 전송된다.
수신지는 이 조각들이 원래 어떤 패킷에서 나뉜 것인지 알아야 한다.
식별자는 이때 사용된다.
같은 원본 패킷에서 나뉜 조각들은 같은 식별자 값을 가진다.
수신지는 식별자를 보고 같은 메시지에서 나온 조각들을 모아 재조합할 수 있다.
원래 패킷 A
조각 1: 식별자 100
조각 2: 식별자 100
조각 3: 식별자 100
플래그
플래그(flags)는 IPv4 패킷의 단편화와 관련된 정보를 나타낸다.
IPv4의 플래그 필드는 3비트로 구성된다.
첫 번째 비트: 사용하지 않음, 항상 0
DF 비트: Don't Fragment
MF 비트: More Fragment
DF(Don't Fragment) 비트는 단편화를 하지 말라는 표시이다.
DF = 1
단편화하지 말 것
DF = 0
단편화 가능
DF 비트가 1인데 패킷 크기가 MTU보다 크면, 해당 패킷은 단편화되지 않고 폐기될 수 있다.
MF(More Fragment) 비트는 뒤에 단편화된 패킷이 더 있는지 알려준다.
MF = 1
뒤에 조각이 더 있음
MF = 0
마지막 조각임
수신지는 MF 비트를 보고 단편화된 패킷이 더 도착해야 하는지 판단할 수 있다.
단편화 오프셋
단편화 오프셋(fragment offset)은 현재 조각이 원래 데이터에서 어느 위치에 해당하는지 나타낸다.
단편화된 패킷들은 수신지에 순서대로 도착하지 않을 수 있다.
예를 들어 첫 번째 조각보다 두 번째 조각이 먼저 도착할 수도 있다.
수신지가 패킷을 올바른 순서로 재조합하려면 각 조각이 원래 데이터에서 어느 위치에 있었는지 알아야 한다.
단편화 오프셋은 이 위치 정보를 제공한다.
조각 1: 원래 데이터의 앞부분
조각 2: 원래 데이터의 중간 부분
조각 3: 원래 데이터의 뒷부분
수신지는 식별자, 플래그, 단편화 오프셋을 이용해 단편화된 패킷을 다시 조립한다.
식별자
같은 원본 패킷에서 나온 조각인지 확인
MF 비트
뒤에 조각이 더 있는지 확인
단편화 오프셋
원래 데이터에서의 위치 확인
TTL
TTL(Time To Live)은 패킷의 수명을 나타내는 필드이다.
네트워크에서는 라우팅 문제 등으로 인해 패킷이 목적지에 도착하지 못하고 계속 떠도는 상황이 생길 수 있다.
이런 패킷이 네트워크에 계속 남아 있으면 자원을 낭비하게 된다.
TTL은 이를 막기 위해 사용된다.
패킷이 라우터를 하나 거칠 때마다 TTL 값은 1씩 감소한다.
TTL이 0이 되면 해당 패킷은 폐기된다.
여기서 홉(hop)은 패킷이 하나의 라우터나 호스트를 거쳐 전달되는 한 번의 이동을 의미한다.
TTL은 패킷이 무한히 네트워크를 떠도는 것을 막는 안전장치이다.
프로토콜
IPv4 헤더의 프로토콜(protocol) 필드는 상위 계층의 프로토콜이 무엇인지 나타낸다.
IP 패킷의 페이로드에는 보통 전송 계층의 데이터가 들어간다.
이 필드는 IP 패킷이 어떤 상위 계층 프로토콜을 캡슐화하고 있는지 알려준다.
예를 들어 TCP는 번호 6, UDP는 번호 17로 표시된다.
수신 측은 이 값을 보고 IP 패킷의 페이로드를 어떤 프로토콜로 처리해야 하는지 알 수 있다.
송신지 IP 주소와 수신지 IP 주소
IPv4 헤더에는 송신지 IP 주소와 수신지 IP 주소가 들어 있다.
송신지 IP 주소는 패킷을 보낸 호스트의 주소이다.
수신지 IP 주소는 패킷이 도착해야 할 호스트의 주소이다.
IP 주소 지정은 이 두 필드를 바탕으로 이루어진다.
라우터는 수신지 IP 주소를 보고 패킷을 어느 방향으로 전달할지 결정한다.
IPv4 주소의 한계
IPv4 주소는 32비트이다.
이론적으로 만들 수 있는 IPv4 주소 개수는 2^32인 약 43억 개이다.
처음에는 매우 큰 숫자로 보였지만, 인터넷에 연결되는 장치가 폭발적으로 증가하면서 부족해졌다.
컴퓨터뿐만 아니라 스마트폰, 서버, IoT 기기, 네트워크 장비까지 모두 IP 주소를 필요로 하기 때문이다.
이 한계를 해결하기 위해 등장한 것이 IPv6이다.
IPv6
IPv6는 IPv4 주소 부족 문제를 해결하기 위해 등장한 IP 버전이다.
IPv4가 32비트 주소를 사용하는 것과 달리, IPv6는 128비트 주소를 사용한다.
128비트는 16바이트이다.
IPv6 주소는 16진수로 표기하며, 콜론으로 구분된 8개 그룹으로 나타낸다.
예를 들어 다음과 같은 형태이다.
2001:0db8:0000:0000:0000:ff00:0042:8329
IPv6가 이론적으로 표현할 수 있는 주소 개수는 2^128개이므로 IPv4보다 훨씬 많은 주소를 표현할 수 있다.
IPv6의 핵심 필드
IPv6 헤더에도 여러 필드가 있다.
여기서는 다음 필드를 중심으로 보면 된다.
다음 헤더
홉 제한
송신지 IP 주소
수신지 IP 주소
다음 헤더
다음 헤더(next header) 필드는 상위 계층 프로토콜 또는 확장 헤더를 가리킨다.
IPv6는 기본 헤더 외에 확장 헤더를 가질 수 있다.
확장 헤더는 기본 헤더와 페이로드 데이터 사이에 위치한다.
필요에 따라 여러 확장 헤더가 꼬리를 물듯 이어질 수도 있다.

대표적인 확장 헤더에는 다음과 같은 것들이 있다.
홉 간 옵션
수신지 옵션
라우팅
단편
ESP
IPv6의 다음 헤더 필드는 그 다음에 어떤 헤더나 프로토콜이 오는지 알려주는 역할을 한다.
IPv6의 단편화
IPv4에서는 기본 헤더 안에 단편화 관련 필드가 들어 있다.
반면 IPv6에서는 단편화가 기본 헤더가 아니라 단편화 확장 헤더를 통해 이루어진다.
단편화 확장 헤더에는 다음과 같은 필드가 있다.

예약 필드는 사용되지 않으며 0으로 설정된다.
단편화 오프셋은 전체 메시지에서 현재 단편화된 패킷의 위치를 나타낸다.
M 플래그는 IPv4의 MF 비트와 비슷하다.
M = 1
뒤에 단편화된 패킷이 더 있음
M = 0
마지막 단편화 패킷
식별자 필드는 같은 원본 메시지에서 단편화된 패킷들을 식별하는 데 사용된다.
홉 제한
IPv6의 홉 제한(hop limit)은 IPv4의 TTL과 비슷한 역할을 한다.
패킷이 하나의 라우터를 거칠 때마다 홉 제한 값이 1씩 감소한다.
값이 0이 되면 패킷은 폐기된다.
이 필드는 패킷이 네트워크 안에서 무한히 떠도는 것을 방지한다.
IPv6 송신지 주소와 수신지 주소
IPv6 헤더에도 송신지 IP 주소와 수신지 IP 주소가 들어 있다.
IPv6 주소는 128비트이기 때문에 IPv4보다 훨씬 길다.
라우터는 수신지 IPv6 주소를 바탕으로 패킷을 목적지 방향으로 전달한다.
IPv4와 IPv6 비교
IPv4와 IPv6의 차이를 간단히 정리하면 다음과 같다.
IPv4
주소 크기: 32비트
표기 방식: 점으로 구분된 10진수 4개
예시: 192.168.0.1
주소 개수: 약 43억 개
단편화 정보: 기본 헤더에 포함
수명 필드: TTL
IPv6
주소 크기: 128비트
표기 방식: 콜론으로 구분된 16진수 8개 그룹
예시: 2001:0db8:0000:0000:0000:ff00:0042:8329
주소 개수: 2^128개
단편화 정보: 단편화 확장 헤더 사용
수명 필드: 홉 제한'STUDY' 카테고리의 다른 글
| [네트워크] 서브넷 마스크와 CIDR 계산법 정리 (0) | 2026.05.28 |
|---|---|
| [네트워크] IPv4 주소 구조와 클래스풀 주소 체계 정리 (0) | 2026.05.28 |
| [네트워크] 캡슐화와 역캡슐화, PDU 정리 (0) | 2026.05.28 |
| [네트워크] 네트워크 참조 모델: OSI 모델과 TCP/IP 모델 (0) | 2026.05.28 |
| [네트워크] 패킷 헤더와 프로토콜: 유니캐스트, 브로드캐스트, 멀티캐스 (0) | 2026.05.27 |