파일 시스템
컴퓨터에서 파일은 보조기억장치에 저장된다.
하지만 보조기억장치에 데이터가 아무렇게나 저장되어 있다면 사용자는 원하는 파일을 찾기 어렵고, 운영체제도 파일을 효율적으로 관리하기 어렵다.
이때 필요한 것이 파일 시스템(file system)이다.
파일 시스템은 파일과 디렉터리를 관리하는 운영체제 내부의 프로그램이다.
보조기억장치에 저장된 데이터 덩어리를 파일과 디렉터리라는 단위로 정리하고, 사용자가 쉽게 접근할 수 있도록 도와준다.
파일을 생성하고, 삭제하고, 열고, 닫는 작업도 결국 파일 시스템을 통해 이루어진다.
파일
파일(file)은 보조기억장치에 저장된 관련 정보의 집합이다.
조금 더 쉽게 말하면, 의미 있고 관련 있는 정보를 모아둔 논리적 단위이다.
예를 들어 사진 파일, 문서 파일, 실행 파일, 소스 코드 파일 등이 모두 파일이다.
파일 안에는 실제 데이터만 들어 있는 것이 아니다.
파일을 실행하거나 관리하기 위한 부가 정보도 함께 존재한다.
파일을 이루는 정보는 크게 두 가지로 볼 수 있다.
파일의 실제 내용
파일의 속성 정보
파일의 속성 정보는 메타데이터(metadata)라고도 한다.
메타데이터는 파일 자체를 설명하는 정보이다.
파일의 속성
파일에는 여러 속성이 저장될 수 있다.
대표적인 파일 속성은 다음과 같다.
유형
크기
보호 정보
생성 날짜
마지막 접근 날짜
마지막 수정 날짜
생성자
소유자
위치
파일의 유형은 해당 파일이 어떤 종류의 파일인지 나타낸다.
예를 들어 실행 파일인지, 소스 코드 파일인지, 문서 파일인지, 이미지 파일인지 등을 구분할 수 있다.
파일의 크기는 해당 파일이 보조기억장치에서 얼마나 많은 공간을 차지하는지를 나타낸다.
보호 정보는 누가 이 파일을 읽거나 쓸 수 있는지, 실행할 수 있는지를 나타낸다.
생성 날짜, 마지막 접근 날짜, 마지막 수정 날짜는 파일이 언제 만들어졌고, 언제 열렸으며, 언제 수정되었는지를 알려준다.
소유자는 해당 파일을 소유한 사용자를 의미한다.
위치는 파일이 보조기억장치의 어느 위치에 저장되어 있는지에 대한 정보이다.
확장자
파일 이름 뒤에 붙는 .txt, .jpg, .exe, .c 같은 부분을 확장자라고 한다.
확장자는 파일의 유형을 알려주는 힌트 역할을 한다.
예를 들어 다음과 같이 구분할 수 있다.
.exe 실행 파일
.obj 목적 파일
.c C 소스 코드 파일
.py Python 소스 코드 파일
.docx 워드프로세서 파일
.dll 라이브러리 파일
.jpg 이미지 파일
.mp4 동영상 파일
.zip 압축 파일
확장자는 파일의 실제 구조를 완전히 보장하는 것은 아니지만, 운영체제나 사용자에게 파일을 어떻게 다룰지 알려주는 중요한 단서가 된다.
파일 연산과 시스템 호출
응용 프로그램이 파일을 직접 마음대로 다루는 것은 아니다.
파일은 운영체제가 관리한다.
따라서 응용 프로그램이 파일을 생성하거나 삭제하거나 읽고 쓰려면 운영체제에게 요청해야 한다.
이때 사용하는 것이 시스템 호출이다.
파일 연산을 위한 대표적인 시스템 호출은 다음과 같다.
파일 생성
파일 삭제
파일 열기
파일 닫기
파일 읽기
파일 쓰기
예를 들어 어떤 프로그램이 파일을 읽고 싶다면 먼저 운영체제에게 파일 열기를 요청한다.
운영체제가 파일을 열어주면 프로그램은 파일 내용을 읽을 수 있다.
파일 사용이 끝나면 파일 닫기를 요청한다.
디렉터리
파일이 많아지면 파일들을 체계적으로 관리할 필요가 있다.
이때 사용하는 것이 디렉터리(directory)이다.
디렉터리는 여러 파일과 하위 디렉터리를 묶어 관리하는 구조이다.
일반적으로 사용자가 말하는 폴더와 비슷한 개념으로 이해하면 된다.
현대 운영체제에서는 디렉터리를 트리 구조로 관리한다.
가장 위에 있는 디렉터리를 루트 디렉터리(root directory)라고 한다.
유닉스 계열 운영체제에서는 루트 디렉터리를 /로 표시한다.
/
├── home
│ └── minchul
│ └── a.sh
├── bin
└── usr
루트 디렉터리 아래에는 여러 서브 디렉터리가 있을 수 있다.
서브 디렉터리는 어떤 디렉터리 안에 포함된 하위 디렉터리이다.
경로
경로(path)는 파일이나 디렉터리의 위치를 나타내는 정보이다.
디렉터리 구조를 따라가면 특정 파일이 어디에 있는지 알 수 있다.
예를 들어 다음 파일이 있다고 하자.
/home/minchul/a.sh
이 경로는 루트 디렉터리 /에서 시작해 home, minchul 디렉터리를 거쳐 a.sh 파일에 도달한다는 뜻이다.
경로는 크게 절대 경로와 상대 경로로 나눌 수 있다.
절대 경로
절대 경로(absolute path)는 루트 디렉터리에서 시작해 파일이나 디렉터리까지 이르는 고유한 경로이다.
/home/minchul/a.sh
절대 경로는 항상 루트 디렉터리부터 시작한다.
그래서 현재 작업 중인 위치가 어디든 같은 파일을 가리킨다.
상대 경로
상대 경로(relative path)는 현재 디렉터리를 기준으로 파일이나 디렉터리의 위치를 나타내는 경로이다.
예를 들어 현재 위치가 /home/minchul이라면, a.sh 파일은 다음처럼 나타낼 수 있다.
a.sh
디렉터리 연산과 시스템 호출
디렉터리도 파일처럼 운영체제가 관리한다.
응용 프로그램이 디렉터리를 생성하거나 삭제하거나 내용을 확인하려면 운영체제에게 요청해야 한다.
디렉터리 연산을 위한 대표적인 시스템 호출은 다음과 같다.
디렉터리 생성
디렉터리 삭제
디렉터리 열기
디렉터리 닫기
디렉터리 읽기
파일과 마찬가지로 디렉터리도 운영체제의 파일 시스템을 통해 관리된다.
디렉터리 엔트리
많은 운영체제에서는 디렉터리를 특별한 형태의 파일로 본다.
일반 파일 내부에는 파일의 실제 내용이 들어 있다.
반면 디렉터리 내부에는 해당 디렉터리에 포함된 파일과 하위 디렉터리에 대한 정보가 들어 있다.
이 정보를 디렉터리 엔트리(directory entry)라고 한다.
디렉터리 엔트리에는 보통 다음과 같은 정보가 담긴다.
디렉터리에 포함된 대상의 이름
그 대상이 보조기억장치 어디에 저장되어 있는지 알 수 있는 정보
예를 들어 /home/minchul 디렉터리 안에 a.sh 파일이 있다면, /home/minchul 디렉터리에는 a.sh에 대한 디렉터리 엔트리가 들어 있다.
운영체제는 이 엔트리를 보고 a.sh 파일의 위치를 찾아간다.
FAT 파일 시스템
이제 대표적인 파일 시스템을 살펴보자.
먼저 FAT(File Allocation Table) 파일 시스템이다.
FAT 파일 시스템은 연결 할당을 기반으로 한 파일 시스템이다.
연결 할당에서는 파일을 이루는 블록들이 연결 리스트처럼 이어진다.
각 블록은 다음 블록의 주소를 가지고 있다.
예를 들어 어떤 파일이 여러 블록에 나누어 저장되어 있다면 다음과 같이 연결된다.

하지만 연결 할당에는 단점이 있다.
파일을 읽으려면 첫 번째 블록부터 차례대로 따라가야 한다.
중간 블록에 바로 접근하기 어렵다.
또한 어떤 블록에 문제가 생기면 그 이후 블록을 찾기 어려워질 수 있다.
각 블록 안에 다음 블록 주소가 들어 있기 때문이다.
FAT의 아이디어
FAT 파일 시스템은 이 단점을 보완하기 위해 다음 블록 주소들을 한곳에 모아 관리한다.
각 블록 안에 다음 블록 주소를 넣는 대신, 파일 할당 테이블에 따로 저장한다.
이 테이블이 FAT이다.
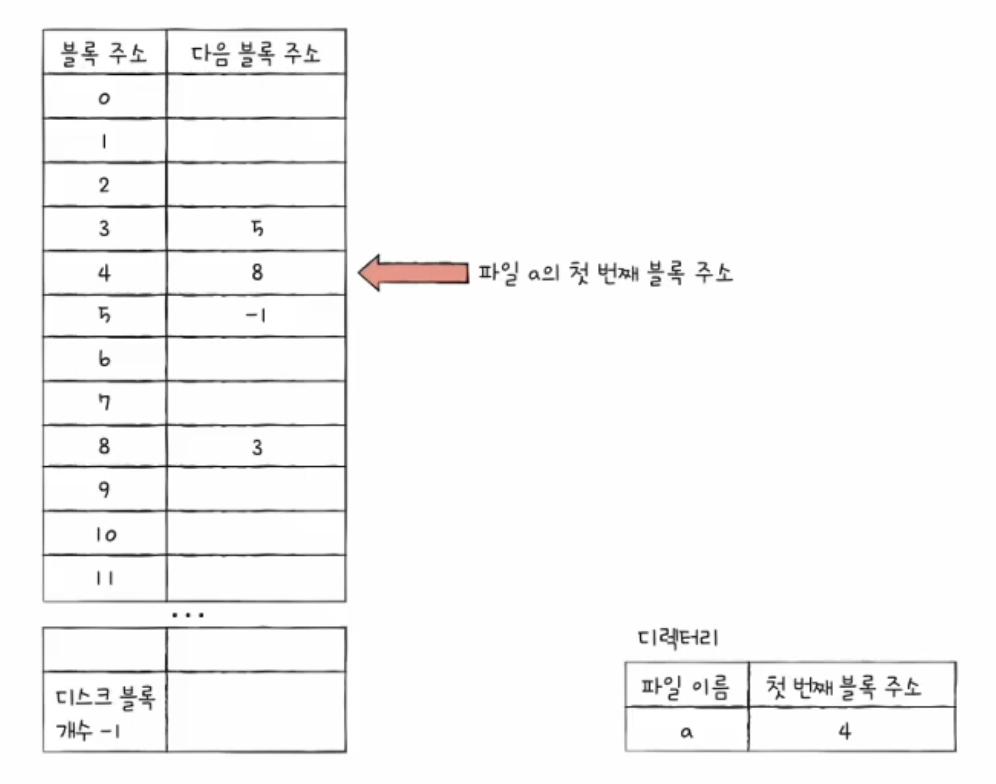
이렇게 하면 각 블록 안을 직접 확인하지 않아도 FAT만 보고 파일의 블록 연결 관계를 알 수 있다.
FAT 디렉터리 엔트리
FAT 파일 시스템의 디렉터리 엔트리에는 파일을 찾고 관리하기 위한 정보가 들어 있다.
대표적으로 다음과 같은 정보가 포함될 수 있다.
파일 이름
확장자
속성
예약 영역
생성 시간
마지막 접근 시간
마지막 수정 시간
시작 블록
파일 크기
여기서 중요한 것은 시작 블록이다.
디렉터리 엔트리는 파일의 시작 블록을 알려준다.
운영체제는 시작 블록을 찾은 뒤 FAT를 참고하여 다음 블록들을 따라가며 파일 전체를 읽는다.

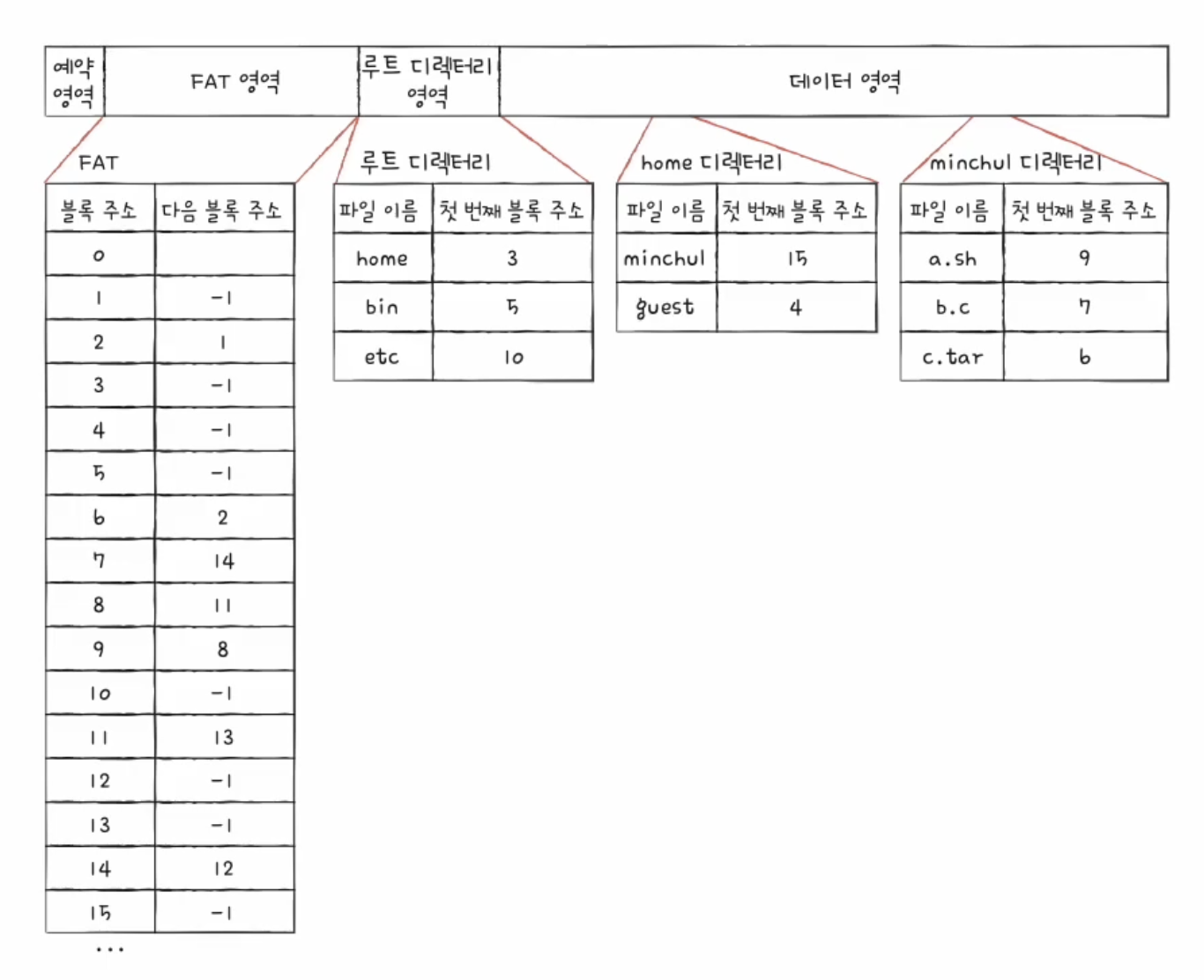
유닉스 파일 시스템
유닉스 파일 시스템은 색인 할당을 기반으로 한다.
색인 할당은 파일의 데이터 블록 주소들을 하나의 색인 블록에 모아두는 방식이다.
유닉스 파일 시스템에서는 이 색인 블록 역할을 하는 구조가 i-node이다.
i-node는 파일의 속성 정보와 데이터 블록 주소를 저장한다.
파일 이름은 디렉터리 엔트리에 저장되고, 파일의 실제 정보는 i-node에 저장된다.
유닉스 파일 시스템의 영역
유닉스 파일 시스템은 보통 다음과 같은 영역으로 나눌 수 있다.
예약 영역
i-node 영역
데이터 영역
i-node와 블록 주소
i-node에는 파일 속성 정보와 함께 데이터 블록 주소가 저장된다.
전통적인 유닉스 파일 시스템에서는 i-node가 15개의 블록 주소를 저장할 수 있다고 설명한다.
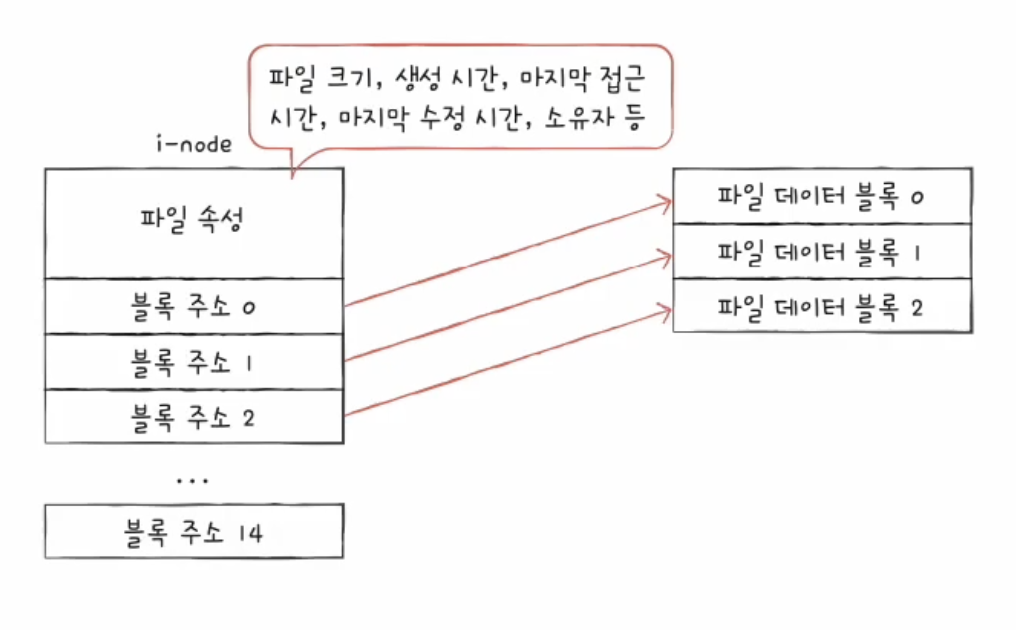
그런데 파일이 매우 커서 15개 블록보다 더 많은 블록을 차지하면 어떻게 할까?
이를 위해 직접 블록, 단일 간접 블록, 이중 간접 블록, 삼중 간접 블록을 사용한다.
1. 직접 블록
처음 12개의 주소에는 직접 블록 주소가 저장된다.
직접 블록은 파일 데이터가 실제로 저장된 블록이다.
파일이 작다면 직접 블록만으로 충분하다.

2. 단일 간접 블록
직접 블록 12개로 부족하면 13번째 주소를 사용한다.
13번째 주소에는 단일 간접 블록의 주소가 저장된다.
단일 간접 블록은 파일 데이터를 저장한 블록들의 주소를 담고 있는 블록이다.
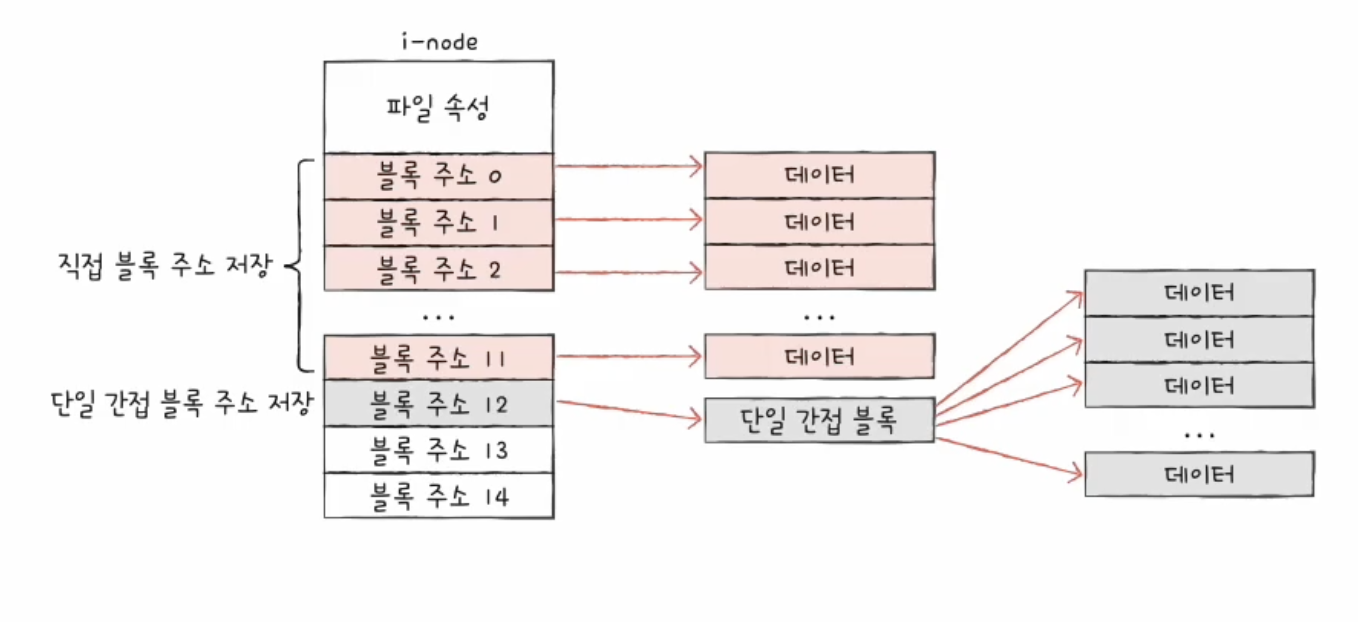
3. 이중 간접 블록
단일 간접 블록으로도 부족하면 14번째 주소를 사용한다.
14번째 주소에는 이중 간접 블록의 주소가 저장된다.
이중 간접 블록은 단일 간접 블록들의 주소를 저장하는 블록이다.
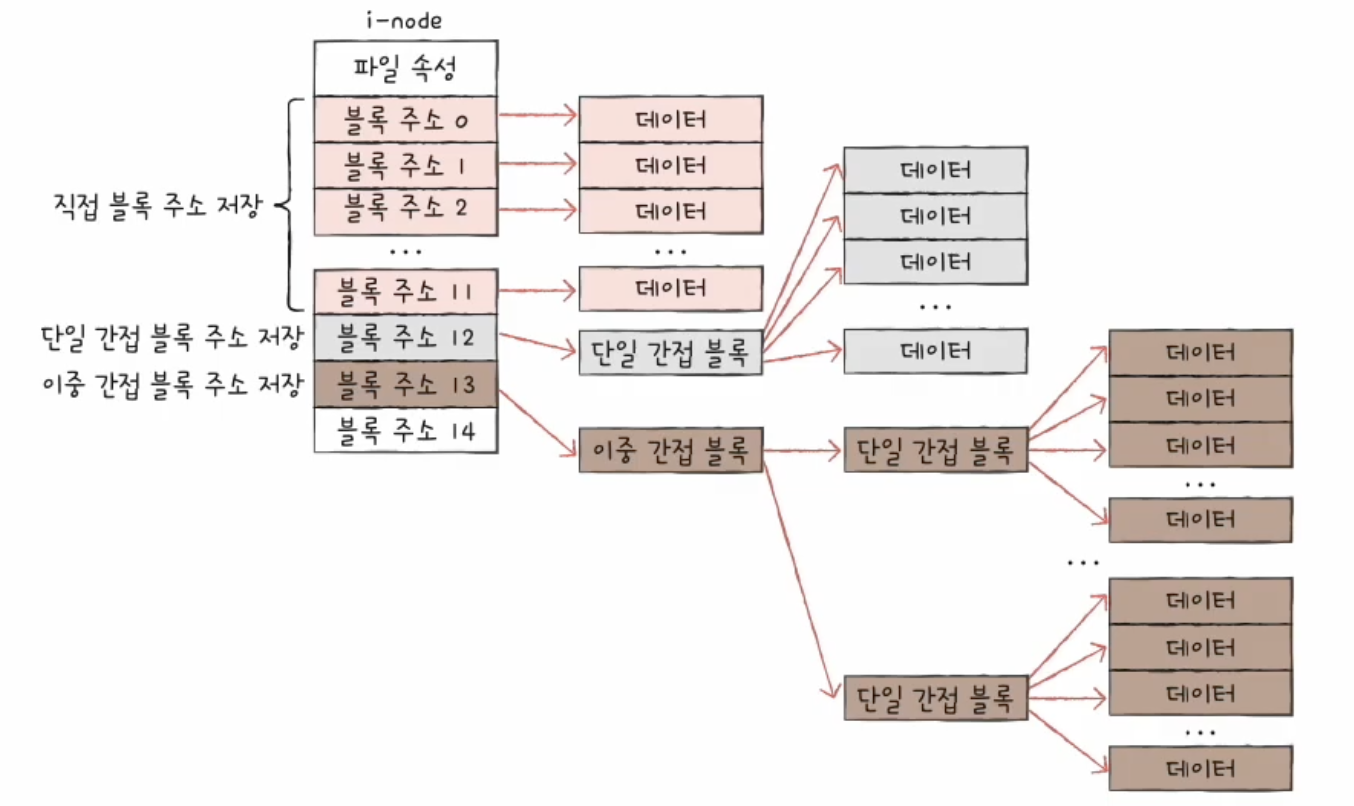
4. 삼중 간접 블록
이중 간접 블록으로도 부족하면 15번째 주소를 사용한다.
15번째 주소에는 삼중 간접 블록의 주소가 저장된다.
삼중 간접 블록은 이중 간접 블록들의 주소를 저장하는 블록이다.

이 구조를 사용하면 작은 파일은 빠르게 접근할 수 있고, 큰 파일도 많은 블록을 연결해 표현할 수 있다.
결국 i-node만 찾으면 해당 파일의 데이터 블록들을 찾아갈 수 있다.

FAT와 유닉스 파일 시스템 비교
FAT와 유닉스 파일 시스템은 파일의 블록 위치를 관리하는 방식이 다르다.
FAT는 파일의 블록 연결 정보를 하나의 테이블에 모아둔다.
유닉스 파일 시스템은 파일마다 i-node를 두고, i-node 안에 데이터 블록 주소를 저장한다.
FAT 파일 시스템
- 파일 할당 테이블로 블록 연결 관리
- 디렉터리 엔트리에 시작 블록 저장
- FAT를 따라가며 나머지 블록 읽기
유닉스 파일 시스템
- i-node로 파일 정보 관리
- 디렉터리 엔트리에 파일 이름과 i-node 번호 저장
- i-node를 통해 데이터 블록 주소 확인'STUDY' 카테고리의 다른 글
| [네트워크] 패킷 헤더와 프로토콜: 유니캐스트, 브로드캐스트, 멀티캐스 (0) | 2026.05.27 |
|---|---|
| [네트워크] 네트워크 기본 개념: 호스트, LAN/WAN, 패킷 교환 정리 (0) | 2026.05.27 |
| [운영체제] 요구 페이징과 페이지 교체 알고리즘, 프레임 할당 정리 (0) | 2026.05.27 |
| [운영체제] 가상 메모리와 페이징: 페이지 테이블, TLB, 페이지 폴트 정리 (0) | 2026.05.27 |
| [운영체제] 교착 상태 해결 방법: 예방, 회피, 검출 후 회복 (0) | 2026.05.27 |